
MicroProcessor Forum 2007レポート
Qualcommの携帯電話向けプロセッサ「Scorpion」
~独自実装で1GHz駆動を実現
 |
会期:5月21日~23日(現地時間)
会場:米カリフォルニア州サンノゼ
DoubleTree Hotel
「Scorpion」は、Qualcommが携帯電話用に開発したプロセッサである。携帯電話のプロセッサには、大きく通信関係を処理するベースバンドプロセッサと、メールソフトなどのユーザーが操作する機能を担当するアプリケーションプロセッサがある。このScorpionは、アプリケーションプロセッサである。ただし、このプロセッサは単体で提供されるのではなく、携帯電話用のプラットフォームSnapDragonの一部として提供される。
このプロセッサは、簡単にいうとARMv7をベースに、浮動小数点処理などの性能強化と、低消費電力化を行なったプロセッサだ。スーパースカラーでアウトオブオーダー実行するなど、性能面でもかなり強化が見られる。プロセッサ自体は、汎用だが、携帯電話用デバイスの一部として提供されるため、高性能スマートフォンなどに採用されることになるはずだ。
●ARMv7を独自に実装
Scorpionは、SnapDragonとよばれる、SoCの一部として提供される。SanpDragon自体は、3dieのスタックパッケージで製造されるのだという。簡単にいえばScorpionは、同社の携帯電話専用デバイスのためのアプリケーションプロセッサであるわけだ。SnapDragonは、CDMA2000やW-CDMA(HSDPAにも)に対応しており、日本国内向けの携帯電話にも採用される可能性はある。SnapDragon自体は、今年の第3四半期にサンプルが登場する予定だ。
さて、このScorpionは、ARMv7に対応したプロセッサだが、QualCommがARMv7-Aをベースに実装を行なっていて、ARMが開発した同じARMv7-A対応のCortex-A8とは実装が違うようだ。Scorpionは、スーパースカラーで投機的アウトオブオーダー実行、レジスタリネーミングを装備する。クロック周波数は1GHz、65nmの低リーク、マルチVtのCMOSプロセスを使って作られる。Qualcomm自体はFabを持っていないため、実際の製造は同社のパートナー企業が行なう。SnapDragonのプレスリリースには、Samsung Electronicsのメッセージが記載されており、同社が製造する可能性は高いと思われる。
消費電力については公開されていないが、0.14mW/DMIPS(DMIPSはDrystone MIPS。DrystoneベンチマークにおけるVAX 11/780との比較値)、最大2,100DMIPS/8,000MFLOPSという値が公開されている。これから計算すると最大で294mW程度と推測される。
Qaulcommによれば、スタンダードな製品は、自社の要求に応えられなかったが、ARMv7が持つTrustZoneやNeonといった機能は必要だったという。まあ、OSなどのサポートを考えると、ARMのような標準アーキテクチャにしておくことは重要で、いまさら携帯電話市場で、新規アーキテクチャというのもありえないだろう。
ただ、すでに開発されているインプリメンテーションがあるのにもかかわらず、独自のインプリメンテーションが必要かどうかは難しいところ。QualCommは、必要な理由として、「低消費電力」というのを挙げている。今回の製品は、携帯電話用であるため、消費電力の削減が必要で、そのために、クロックゲーティングなどを細かく制御したかったというのが独自実装となった最大の理由だろう。
設計時にすべてのレジスタにクロックゲーティングを入れ、低消費電力向けに最適化を行なったという。また、使われていないデータパスは、休止状態にするなどの対策も行なわれている。内部クロックはゲーティングや周波数変更が可能なように領域別になっている。これにより、整数パイプ、浮動小数点パイプ、L2キャッシュ、トレースロジックなどの領域別、あるいはプロセッサコア、システムインターフェース、デバッグ用ロジックといったクロックドメイン別にダイナミックなクロックゲーティングや最適周波数選択が可能になる。
電源電圧は3段階の選択が可能で、内部は、ドメインごとに複数の電圧を利用できるようにしてあるという。また、指定された条件を満たす、最低の電圧に調整ができるという。そのほか、電圧ドメイン、クロックドメインの管理は、ソフトウェア側から可能だという。
ただ、スペック的なところだけを見ると、ARMのCortex-A8と非常に似ている。ARMのカタログによれば、65nmプロセスで1GHzを達成可能で、消費電力は、300mW以下、最高性能も2,000DMIPSであり、Scorpionとは100DMIPSしか違わない(とはいえVAX-11/780が100台分と考えると大きな違いだが)。
 |
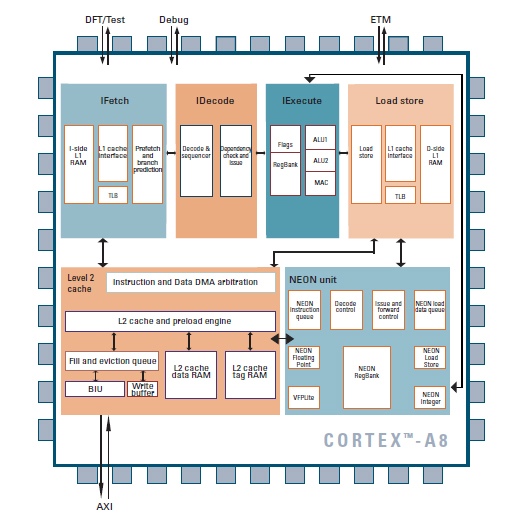 |
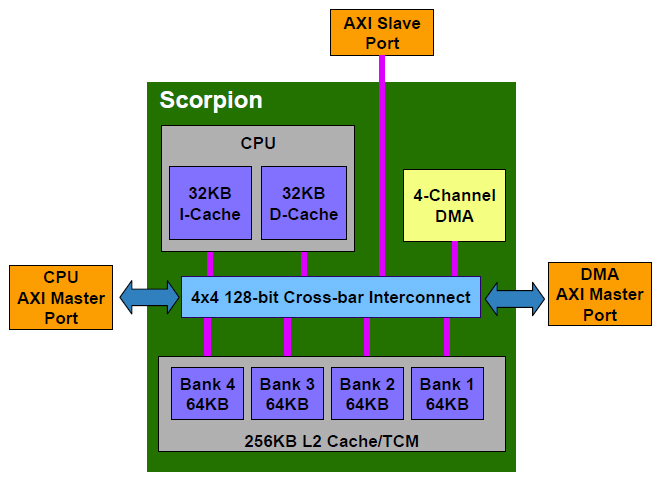
| Scorpionプロセッサは、256KBの2次キャッシュを持ち、メモリ側との接続にはAXIポートを利用する。内蔵のDMAコントローラーは、SIMD演算時にL2(TCM。後述)を介してデータを転送するようになっている | ARMがARMv7の実装として開発したCortex-A8プロセッサ。NEON Unitは、浮動小数点演算、SIMD演算のための機構である |
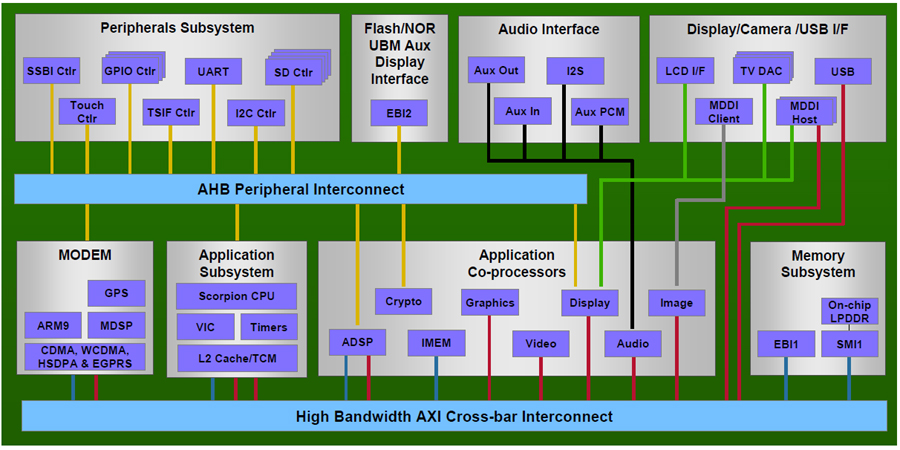 |
| Scorpionは、Qualcommの携帯電話向けSoCであるSnapDragonの一部として提供される |
●メインパイプライン
まずは、Cortex-A8とパイプラインなどを比較してみよう。これをみるとScorpionのパイプラインはかなり複雑な印象を受ける。特に、浮動小数点やSIMD演算の部分のパイプラインが長く、なんだかアンバランスな印象を受ける。ただ、図としては、Cortex-A8のものは、分割されたものしか提供されていないため、多少すっきりしているように見えるが、単純な構造ではない。
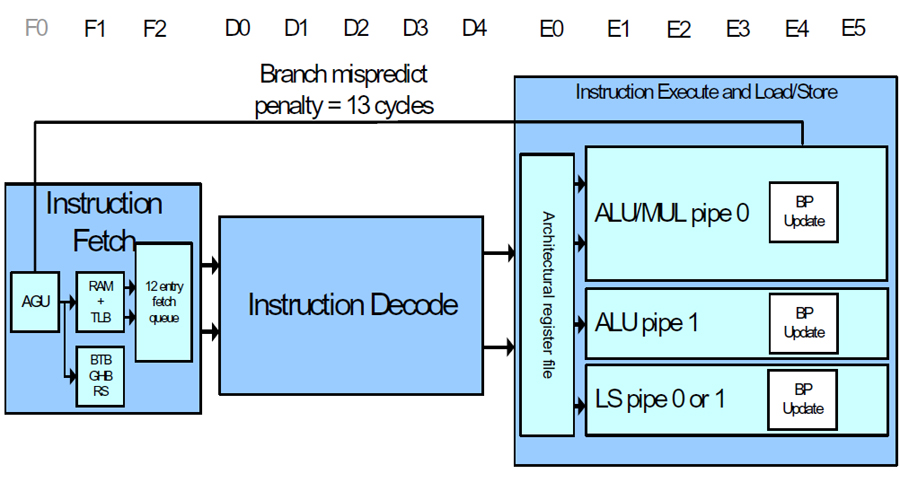
Scropionのパイプラインは、図A上部にある緑の部分が命令フェッチ/ブランチ、その下の黄色い部分が命令実行(整数演算とロードストア命令処理)パイプライン、左側の青い部分がデータアクセス、右側の茶色い部分が浮動小数点/SIMD演算パイプラインである。整数演算パイプラインは、左側がロードストア命令用、右側が演算命令用である。
ロードストアユニットで13ステージ、整数演算は、10または12ステージ、浮動小数点は23ステージと長い。パイプラインが長いのは高クロックを狙っているためである。Scorpionは、最高1GHzと、かつてIntelがXscaleでデモしてみせたクロック周波数を達成する。このためにはどうしてもパイプラインを長くする必要がある。
Scorpionは、スーパースカラーでアウトオブオーダー、投機実行、レジスタリネーミングを行なう。
ARMアーキテクチャは、1命令で最大3つのレジスタを参照し、2つのレジスタを書き換える(例外あり)。このため、これを16個の汎用レジスタに対して行なうため命令間の依存関係はかなり高くなりそうだ。ただ、各命令に実行条件がついているため、投機的実行は割とうまく働くかもしれない。実行条件は、キャリーフラグなどの演算結果によって、後続の命令を実行するかどうかを決めるものだが、これを使うと、1つしかないカレント状態レジスタ(CPSR)への依存関係ができてしまう。しかし、投機実行ができるなら、演算だけを先にやっておいて、直前の演算命令が完了したら、フラグによって結果を廃棄するかどうかを決めればいい。もちろん、実行条件がついていなければ、そのままリタイヤしてしまえばいいわけで、他のプロセッサのように、条件判断命令+ブランチといった組み合わせよりは、制御がしやすいだろう。
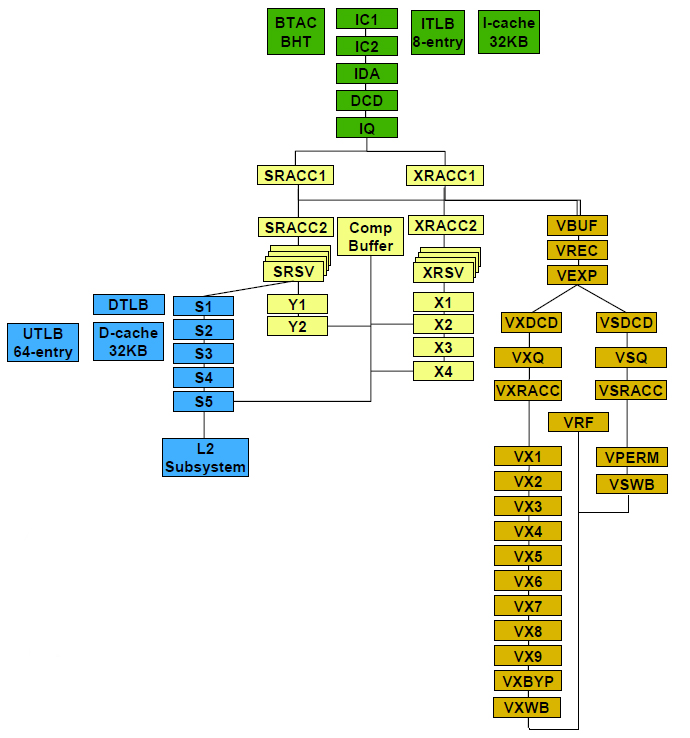 |
| 【図A】Scorpionのパイプラインは、上が命令フェッチ機構、右側が浮動小数点演算とSIMD、左側がデータアクセス機構で、その中心に演算命令とロード/ストア命令用の2つの命令実行パイプラインを持つ |
 |
| Cortex-A8の命令実行パイプライン。乗算可能なpipe0と、通常演算可能なpipe1およびロードストア用のパイプラインで命令を実行する |
 |
| Cortex-A8のNEONユニットは、整数系の実行パイプラインとは別になっている |
ARMv7は、15個の汎用レジスタとプログラムカウンタをr0~r15に割り当てている。r15がプログラムカウンタだが、r14、r13は、戻りアドレスを格納するリンクレジスタ、スタックポインタとして利用する。このため、この2つのレジスタは、CPUの動作モードにより自動的に切り替わるようになっている。また、高速割り込みモードでは、r8~12も切り替わる。つまり、ARMv7には、32個(15+5+2*6)の汎用レジスタがあることになる。
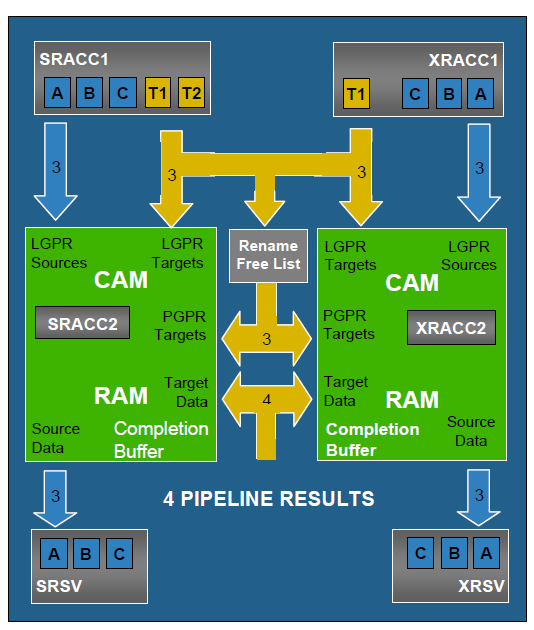
ScorpionはレジスタリネーミングにCompletion Bufferを使う。これは、連想メモリ(CAM:Content Addressable Memory)を使い、物理レジスタ番号と論理レジスタ番号を対応させるもの。物理レジスタ番号が通常のメモリでいうアドレスに相当し、論理レジスタ番号がメモリ内に記録されていて、外部から論理レジスタ番号でもアクセスが可能になっているわけだ。
物理レジスタは64個ある。論理レジスタの32個の倍しかないが、ARMアーキテクチャでは一度に見えるのは最大でr0~r15の16個で、このうちr15はプログラムカウンタなので、リネーミングの対象外。それ以外の17個のレジスタは、割り込みなどのモードで自動的に切り替わるので、数命令程度ならこれで十分だろう。
このCompletion Bufferは、同じものが2つあり、演算、ロード/ストアパイプライン用になっている。ターゲットデータの書き込みは、双方同時に行なわれるため、一貫性は保持される。
なお、ターゲットレジスタ番号は、フリーレジスタリストを介して物理レジスタ番号に変換される。通常演算命令では、ターゲットレジスタは1つだが、ロードストア命令では、自動インデックス(レジスタを介したメモリアクセスの前後にレジスタ値を更新し、次のメモリ位置を指すように変更する)があるため2つのターゲットレジスタが指定できる。
なお、ARMには、最大16個(r15であるプログラムカウンタを含む)のレジスタにデータを読みこむLDM命令がある。この命令は、pop命令や、割り込みなどからの復帰などに使われる。前述のレジスタリネーミング機構は、命令からの書き換えターゲットの指定は最大3つ、ターゲットへの書き込みは最大4つを並行して行なえるようになっている。また、この命令のデータ転送元は必ずメモリになるので、最悪、メモリからの読みこみ時間がかかる。また、書き換え対象にr15が含まれているなら、これはジャンプ命令を実行したのと同じである。ただし、数個程度のレジスタへのロードにこの命令を使う可能性はある。
しかし、この命令のためだけにリネーミング機構を複雑にするのもそのコストを考えると無駄な感じがある。たぶん、この命令は、特別扱いされているのではないかと思われる。
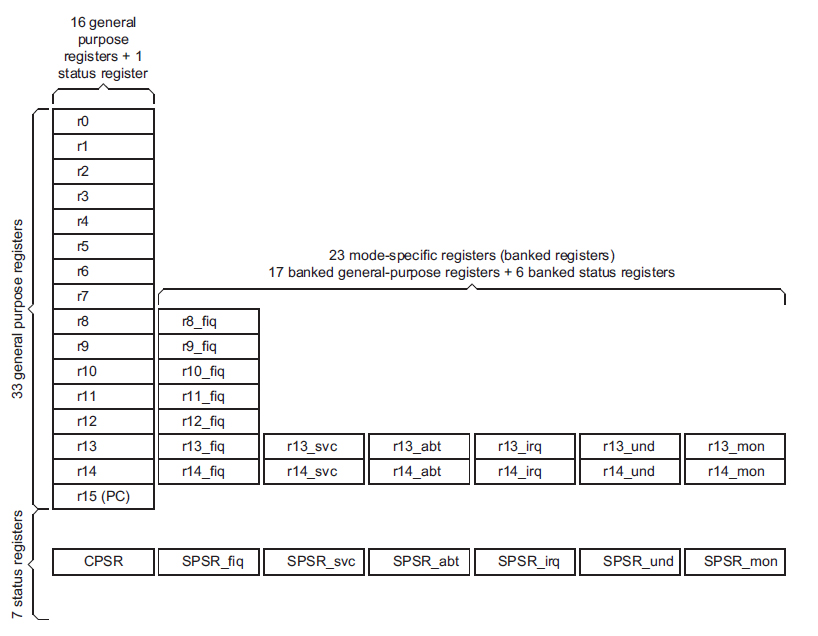 |
| ARMv7では、可視のレジスタはr0~r15とCPSRだけだが、r13,14は動作モードによって自動的に切り替わるバンク構造になっている。また、高速割り込みモードでは、r8~r12も自動的に切り替わる。CSPRも各モードごとに用意されている |
 |
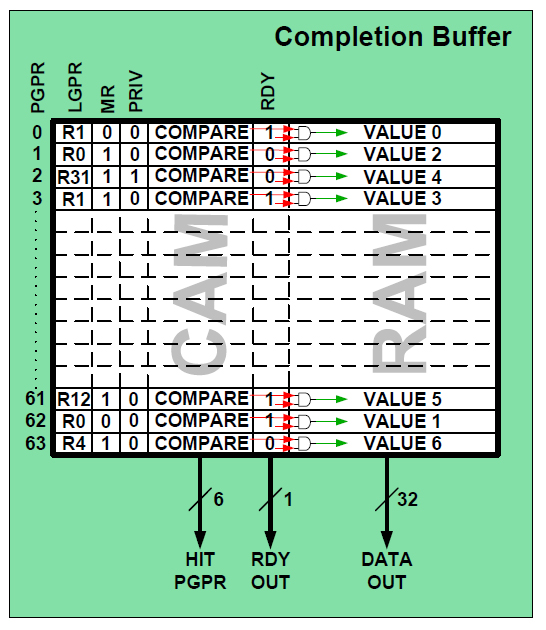 |
| Completion Bufferは、メインパイプのSRACC2/XRACC2とSRSV/XRSVの間にある。これが物理レジスタであり、具体的には連想メモリが使われている。演算パイプ用とロード/ストアパイプ用の2つあり、双方で同じ値を保持している。書き込み対象となるターゲットレジスタに対しては、データアクセス部のS5、ロードストアパイプのY2、整数演算パイプのX2、X4の4カ所からの書き込みを受け付ける | Completion Bufferを構成する連想メモリ内には、論理レジスタ値や保持している値、書き込み完了を表すRDYフラグなどが保持されており、物理レジスタ番号だけでなく、論理レジスタ番号でもアクセスが可能。ソースレジスタの参照では、該当の物理レジスタのRDYフラグが1になっていなければ、データが出力されず、リザベーションステーション(SRSV、XRSV)にある命令の実行が待たされる |
Scorpionは、各ステージ24 FO4(FO4とは4つのゲートをドライブできる出力性能を持つゲートを指す。遅延などの設計ではこのFO4性能を持つインバータを単位に遅延時間などを計算する)で設計されているという。Qualcommの設計チームによれば、利用可能なプロセスで低電圧で高クロックそして電力利用効率を最大化するには20~25FO4が最適値なのだという。プロセス、メーカーなどによる違いはあるが、FO4のインバーターの遅延は、65nmプロセスでは13ps(ピコ秒)程度。25FO4では325ps、つまり計算上は、3GHz程度で動作できる。これに対して余裕のある1GHzで動作させれば、消費電力で有利になるわけだ。
また、Scropionは、256KBのL2キャッシュを内蔵する。これは、L2キャッシュであるとともに64KBの4バンクに分割でき、それぞれをTCM(Tightly-Coupled Memory)として利用できる。これは、L1と一貫性を保ちつつ、SIMD演算時に、内蔵のDMAコントローラによりSIMD演算パイプへのデータ供給を行なう。L2/TCMは、CPU、内蔵DMA、AXIスレーブポートからのマルチポートアクセスが可能になっており、外部コプロセッサとのやりとりやメインメモリとのデータ転送を内蔵の4チャンネルDMAコントローラが自動的に行なう。この動作は、CPUからは透過的になっていて、制御を必要としない。
メモリ側とは64bitのAXIポートが2つあり、1つはCPU、もう1つは内蔵DMAコントローラが利用する(AXIについては関連記事を参照されたい)。
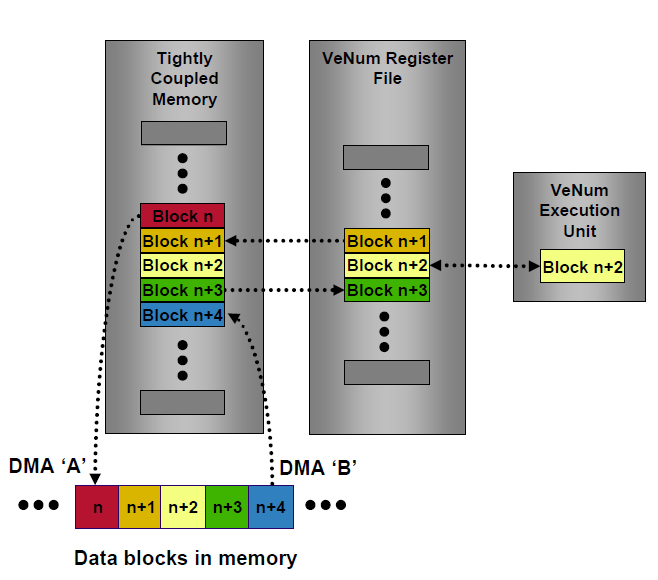 |
| SIMD演算時には、メモリと大量のデータをやりとりする必要があるが、これには、L2の一部をTCM(Tightly-Coupled Memory)として使い、こことメモリ間の転送は、内蔵のDMAコントローラが自動的に行なう |
●VeNum Multimedia Engine
Scorpionで特徴的なのが、浮動小数点やSIMD演算を行なうVeNumエンジンである。VeNumとは「Vector Numerics」の略だという。これは、命令としてはARMv7のVFPv3とNEONを実行する。つまり、ソフトウェア的には、ARMv7と同じだが、実行エンジン(パイプライン)は、ARMのCortex-A8と違うということだ。
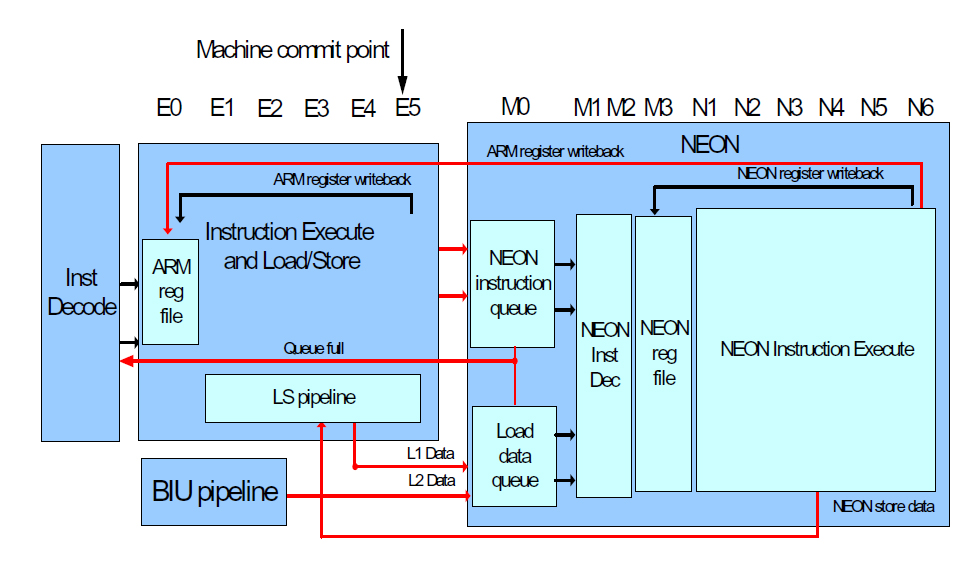
このパイプラインは、大きくVX、VSの2つあり、図Bの左側が演算パイプ、右側がロードストアのパイプラインである。
SIMD演算は、整数(16×8bit、8×16bit、4×32bit)、単精度浮動小数点(4×32bit)を対象とする。また、メモリ上のフォーマットとしては、精度が半分のFP-16形式をサポートしており、内部で32bitへ変換して演算を行なうが、あくまでもメモリ上のフォーマットであり、演算対象にはならない。メモリ上のデータサイズが半分になり、消費電力の観点からは有効な形式なのだという。
パイプは、命令デコード以後は、アウトオブオーダー実行となっているが、浮動小数点処理では投機実行はしない。これは、消費電力という点でみると、結果を放棄するのは無駄な電力となるからだという。
28エントリまでの命令バッファがあり、ここに入った命令は、以後整数コア(CPU)側とは独立して処理される。逆に、VeNumを使わない場合には、パイプライン全体がアイドル状態になり、クロックが停止される。
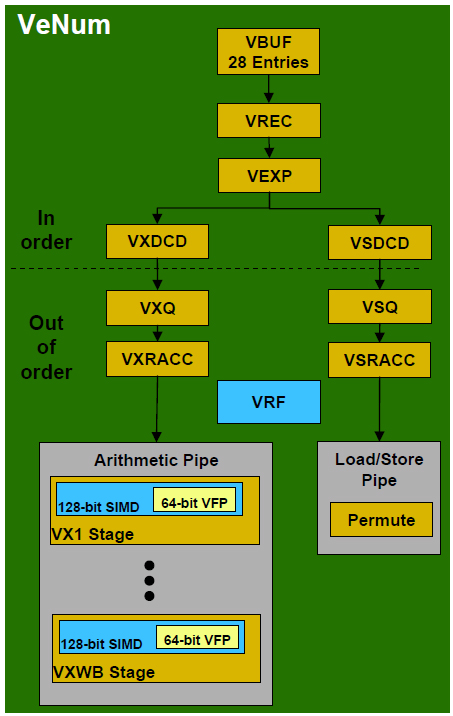 |
| 【図B】Scorpionの浮動小数点/SIMD(NEON)のパイプライン。演算系とロードストア系の2つのパイプがあり、基本的な考え方は、整数部と同じ。ただし、アウトオブオーダー実行はするものの、投機的実行は行なわない |
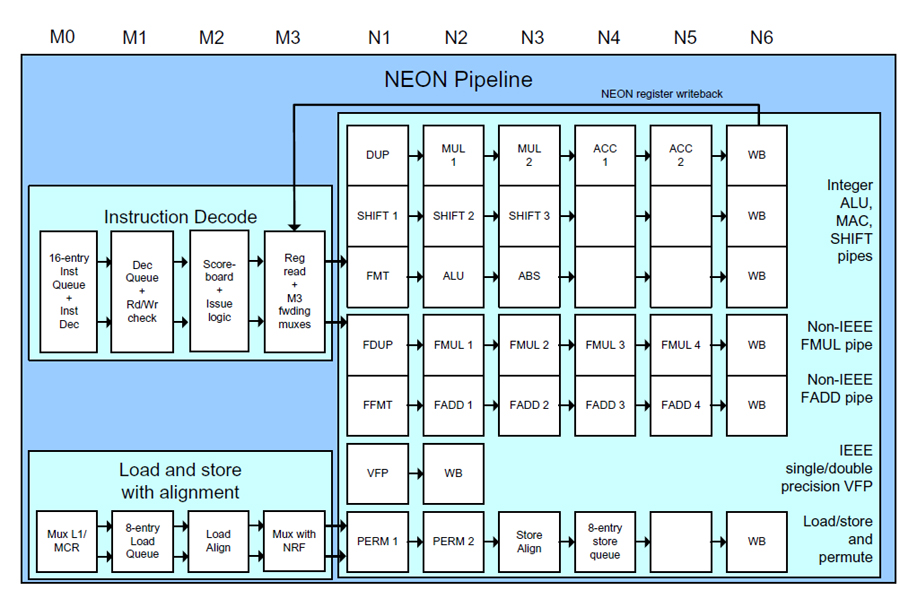 |
| Cortex-A8のNEON Unitは、演算系が6つ、ロードストアで1つの内部パイプラインを持つ。N1~6が、ScorpionのVX1~VXWBに相当する |
このVeNumを使うことで、400MHzのARM1136とグラフィックス演算などでは最大35倍以上の性能が得られ、また、これまでのARM11では、MPEG-4のデコード(CIF、30fps)がほぼ手一杯だったのに対して、Scorpionでは、エンコード、デコードを同時に行なっても、かなり余裕があるという。もちろん、最大クロックが1GHzというのもあるが、マルチメディア処理で4倍程度の速度差があるのが大きな理由だ。
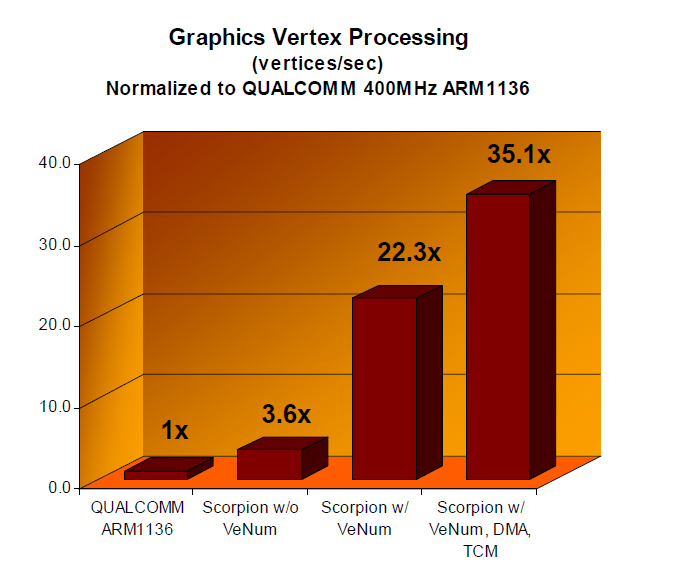 |
| ScorpionとARM11との比較。Qualcommが利用している400MHzのARM1136とScorpionの性能比較。VeNumとDMA、TCMを使った場合、3次元の頂点演算で最大で35.1倍の性能があるという |
今回のMPFでは、ARMがマルチコア拡張、Qualcomが独自実装の1GHz動作プロセッサと、かなりパフォーマンスを重視した方向が見られた。携帯電話など、バッテリ駆動の組み込み系プロセッサでもかなりパフォーマンスが必要になってきたからだろう。スマートフォンはもちろんだが、たとえば、地デジやDVB-H、あるいはQualcommのMediaFLOのように、ストリーミングデータをエンコードし続けるような機能が要求されてきているからだろう。Intelがそのパフォーマンスを組み込みやモバイルへと展開してきているが、対するARM側も対策はあるというところか。
□Microprocessor Forum 2007のホームページ(英文)
http://www.in-stat.com/mpf/07/
□関連記事
【5月30日】【MPF】ARMv7のマルチプロセッサ拡張
http://pc.watch.impress.co.jp/docs/2007/0530/mpf06.htm
【2003年6月19日】【EPF】ARMが3つの機能拡張を発表
http://pc.watch.impress.co.jp/docs/2003/0619/epf01.htm
□MicroProcessor Forum 2007レポートリンク集
http://pc.watch.impress.co.jp/docs/2007/link/mpf.htm
(2007年6月8日)
[Reported by 塩田紳二]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp お問い合わせに対して、個別にご回答はいたしません。
Copyright (c)2007 Impress Watch Corporation, an Impress Group company. All rights reserved.