 |


■後藤弘茂のWeekly海外ニュース■Intelのもう1つの次世代CPU「LPP」 |
●最初のターゲットはUMPC(Ultra Mobile PC)
Intelは、「LPP(Low Power Processor)」または「LPIA(Low Power Intel Architecture)」と呼ばれる、IA-32系命令セットアーキテクチャの超低消費電力CPUをフロムスクラッチ(ゼロから)で開発している。この新CPUは、PC向けCPUと基本的に同レベルのフィーチャを備えながら、0.5~1Wクラスの消費電力になるとされている。従来のIA-32系CPUと比べると、極端に消費電力が低く、伝統的なPC以外の携帯デバイスを主なターゲットとしたプロセッサだ。消費電力とTDP(Thermal Design Power:熱設計消費電力)を下げることで、携帯機器から、組み込みシステム、エマージング市場向けコンピュータなど、さまざまな新市場を開拓する。
Intelは、このLPP/LPIAを、まず「UMPC(Ultra Mobile PC)」向けとして投入する。LPP/LPIAを製品とする事業部「Ultra Mobility Group」がIntel内部に作られている。担当役員は、元Intelのモバイル部門を担当していたAnand Chandrasekher(アナンド・チャンドラシーカ)氏(Senior Vice President, General Manager, Ultra Mobility Group)だ。
9月に行なわれたIntel Developer Forum(IDF)では、Paul S. Otellini(ポール・S・オッテリーニ)氏(President & CEO)がキーノートスピーチで、UMPCなど携帯デバイス向け製品の簡略なロードマップを示した。
 |
 |
| Otellini氏(左)、Chandrasekher氏(右) | IDFで示された次世代UMPC |
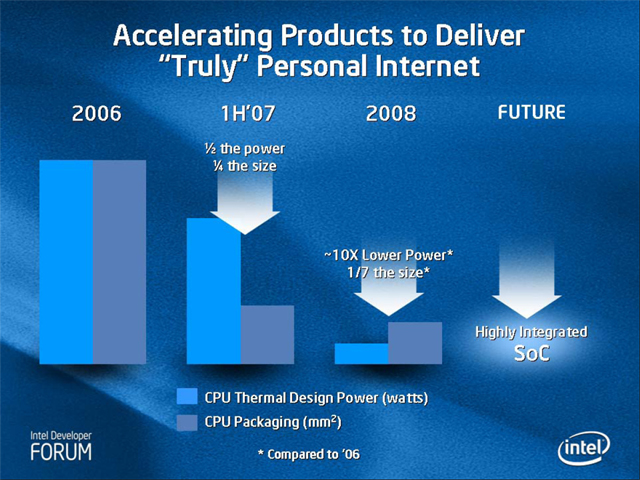
「今年(2006年)をベースラインとすると、5WのULVマイクロプロセッサがベースラインとなる。来年(2007年)には、我々は電力を半分に、実装面積を1/4にしたものを出す。2008年には、今日の製品より、1/10に電力を削減、1/7にサイズを削減するという、我々のゴールに達するだろう。さらに2008年から先では、シングルチップインテグレーションへと移行する計画だ」(Otellini氏)
ラフに言うと、3ステップでIntelは、x86 CPUの超低消費電力化を進める。(1)ホップが2007年前半でTDPが2.5Wクラスで、パッケージサイズが17.5mm角と推測される製品。(2)ステップが2008年でTDPが0.5Wクラスで、パッケージが13mm角と推測される製品。(3)ジャンプがその先、おそらく2010年前後で、CPUに周辺回路を統合したシステムオンチップ(SoC)製品だ。SoCになると外部バスの削減などでトータルの消費電力が下がり、パッケージ個数が減ることでボード上の実装面積が大幅に減る。つまり、より低い消費電力、より小さな実装面積へと、ひたすら向かう計画だ。
 |
| Accelerating Products to Deliver PDF版はこちら |
 |
| 10× Lower Power PDF版はこちら |
 |
| Next Generation Mobility PDF版はこちら |
Intelは、現在、モバイルPC向けCPUで、ULV(超低電圧)版を5WのTDPで提供している。5Wが、メインストリームのIntel x86 CPUの最低TDPラインだったわけだ。しかし、現在、Intelは、この5Wの下のTDP帯のCPUを、UMPCやその種の携帯コンピューティングデバイス向けとして開発している。TDP階層的には、5Wから35W帯がMobility Groupで、その下がUltra Mobility Groupの担当になると推測される。
●2年以上前から始まったプロジェクト
Intelは、2年前の2004年秋頃から0.5~1WのCPUの開発を行なっていることを明らかにしていた。しかし、LPP/LPIAは、2004年後半の段階では、まだリサーチ段階で、IntelのSystems Technology Labが担当していた。2005年に入ってから事業部に移され開発フェイズに入ったという。LPPはコアが小さいため開発は比較的容易なはずだが、それでもCPU開発サイクルから計算すると、製品として登場するのは2008年になるはずだ。
そのため、IntelのUMPC向けの3ステップの製品計画のうち、2007年前半のホップは、既存アーキテクチャCPUの電圧をギリギリまで落としたCPUになると推測される。新しいLPPコアに移行するのは、2008年のステップになると考えるのが妥当だろう。SoCは、LPPのコアに各種インターフェイスやグラフィックスコントローラなどを統合すると見られる。
LPPについては、2004年当時、Systems Technology Labを率いていたIntelのJustin R. Rattner(ジャスティン・R・ラトナー)氏(現Intel Senior Fellow, Director, Corporate Technology Group)に概要を聞いたことがある。2004年秋のインタビューでは、Rattner氏は次のように語っていた。
「我々は、Intelアーキテクチャ(IA)を、もっともローパワー(低消費電力)のスペースまでもたらすことを考えている。つまり、Intelアーキテクチャとフル互換のデバイスを、5W以下のレベルに持って行く。将来、非常に小さな機器にも、Intelアーキテクチャのプロセッサを搭載できるようになるだろう」
ちなみに、Rattner氏はこの時、LPPの機能についてもコメントしている。
「ローパワーと言ってもフィーチャは犠牲にしない。我々は、全ての"T(Technology)"、つまり、HT(Hyper-Threading)、VT(Vanderpool)、LT(LaGrande)、さらにCT(Clackamas)と呼んでいた64bit技術まで、すべてをローパワープロセッサに搭載できると考えている」
実際の製品計画で、これらの技術を全て実装するかどうかはわからない。現実問題として、まだ重要度が低い機能があり、実装するとしても段階的になることが予想される。
また、Rattner氏がフル互換と言っているのは、機能だけでなく、性能レベル的な面も含んでいると見られる。実際、Intelは、LPPを含むUMPC向けのプロセッサについて通常のWindowsが動作できるパフォーマンスだと説明している。PC向けのローエンドCPUとのパフォーマンスギャップは、最小限にする計画のようだ。
 |
| Justin Rattner氏。2006年のIDF Fall Research & Development Keynoteより |
●活きるXScaleでのレッスン
携帯機器向けのローパワープロセッサでは、従来はARM系とMIPS系、SH系などが主流となっていた。つまり、RISC(Reduced Instruction Set Computer)系命令セットアーキテクチャ(ISA:Instruction Set Architecture)が占有していたわけだ。一般に、RISC系アーキテクチャの方が低消費電力化では有利だと考えられていた。x86のようなCISC(複雑命令セットコンピュータ)型アーキテクチャは、CPUが複雑になるため不利だという意見が多かった。
実際、Intel自身も、一度はARMアーキテクチャの「XScale(旧StrongARM2系)」でこの市場を狙った。しかし、現在のIntelは方向を転換、IA-32アーキテクチャで、アンダー1Wのレンジも狙うことにした。
「ハイパフォーマンスプロセッサでも、CISCは絶対にRISCに競合できないと言われていた。ところが、Pentium Proが登場したら、当時のどのRISCプロセッサよりも速かった。現在、業界の多くの人は、Intelアーキテクチャがローパワースペースに入ることはできないと考えている。しかし、私は、ハイパフォーマンススペースで成し遂げたのと同じことを、今回も達成できると考えている。少なくとも、Intelアーキテクチャ自体にはローパワープロセッサ(LPP)に入るための実装上の壁はない。我々はXScaleを開発して、ローパワープロセッサ(LPP)の設計上の問題点は十分に理解した」とRattner氏は語っていた。
ARMのライセンスを受けた時は、Intelが他社命令セットのCPUを作ると話題になった。しかし、結局、x86に戻ってくるあたりはIntelらしい。しかし、Intelは低消費電力でのCISCの不利をカバーできる道を見つけたのだろうか。
●CISCアーキテクチャの有利と不利
消費電力上で、CISCの第1の弱点は、複雑な命令セットに起因するデコードのオーバーヘッドだ。Core Microarchitecture(Core MA)でも、命令デコードに非常に多くのリソースを割いている。これについてRattner氏は次のように語った。
「確かに、(CISCであるIA命令セットの)可変長命令のデコーダは、(固定長命令のRISCのデコーダ)より電力を消費する。IntelやAMDのプロセッサのサーマルマップ(温度分布図)を見れば、チップ上の最も熱いエリアがデコーダ部分であることがわかる。
ここで重要なのは、プロセッサのパフォーマンスは平均消費電力で制約されるのではなく、ピーク温度で制約されることだ。そのため、ホットスポットであるデコーダが、CPUの動作周波数の制約になる。なぜなら、その部分のジャンクション温度が既定値を超えないようにしなければならないからだ。そうした意味では、ISA(の違い)はゼロコストではない。デコーダの電力効率に関しては、固定長命令セットアーキテクチャの方がどうしても有利になる。
もう1つの要素はキャッシュアクセスだ。Intelアーキテクチャでは、よりキャッシュインテンシブになる。レジスタファイルが少ないためで、それがデータキャッシュに負担をかける。それに対して、(RISC系CPUのように)レジスタファイルが大きいと、データキャッシュへの負担は小さくなる。その方が、電力消費の面では有利だ。ここにもトレードオフがある。
これらのペナルティは、電力&面積効率の面からは、おそらく10~20%のレンジだと思う。正確な数字を出すのは難しいが、ゼロコストでないことは確かだ」
命令セットアーキテクチャの違いで、x86系の方がダイ(半導体本体)面積や電力では不利になると認めている。ただし、その差は10~20%程度とも指摘している。また、デコーダがホットスポットになることで、周波数を上げにくい問題も生じることを認めている。LPPのようなCPUは、消費電力自体は小さくても小型になるため電力密度が高くなりやすいので、これも影響すると見られる。しかし、Rattner氏は、逆にCISCが有利になる点もあると語る。
「パフォーマンス面を見ると、面白い逆転がある。CISCは、RISCよりもより多くの命令を実行できるからだ。これは、CISCの方がコード密度(プログラムサイズ当たりのオペレーション数)が高くなるからだ。この問題を解決するために、ARMアーキテクチャはThumb命令セット(16bitのサブセット命令)を開発しているが、一般的にCISCの方が有利となる。
電力効率で見ると、実行する命令はできるだけ少ない方が有利だ。そのため、ここでは逆に可変長が有利になる。こうしたトレードオフの結果、ローパワーの固定長命令セットプロセッサに対して、ローパワーのIntelアーキテクチャプロセッサも競争できるだろう。ダイサイズは多少(RISCより)増えるが、十分、競合できる範囲だと考えている」
CISCの方が同じ処理をする場合でも命令数やプログラムのサイズを小さくできる。そのため、より少ないメモリ、より少ないフェッチ幅、クロック周波数などですむ。そのため、CISCの不利がある程度相殺されると指摘しているわけだ。
●アウトオブオーダやディープパイプラインなどが焦点
では、IntelはどうやってIA-32プロセッサを、0.5Wのスペースに押し込むつもりなのだろう。Intel CPUが肥大化して消費電力が増えたのは、パフォーマンスを高めるために、アウトオブオーダ(out-of-order)型実行のスーパースカラアーキテクチャを発展させたためだ。命令を動的に並べ替えて実行するアウトオブオーダはコストが高く、CPUを肥大化させてしまう。また、高クロック化のためにパイプライン段数も深めたことも肥大化と消費電力増大の原因となっている。パイプライン段数が増えたことで回路数が増え、また、CPU内のリソースもより多く必要になった。高クロック化によるメモリギャップを埋めるために大容量のキャッシュや、高度な分岐予測機能も必要となった。
こうした拡張によって、CPUパフォーマンスは上がったが、パフォーマンス/消費電力とパフォーマンス/トランジスタは急激に悪化してしまった。つまり、パフォーマンスは上がったものの、効率の悪いCPUになってしまった。そのため、論理的には、逆のコースを辿って、CPUをシンプルにすれば、CPUの効率を上げて、パフォーマンスの割に消費電力とトランジスタ数の少ないCPUを作ることができる。
まず第1のポイントは、アウトオブオーダを止めるかどうか。アウトオブオーダはコストが高く、CPU効率を落とす最大の原因となっている。これを削減すれば、効率は大幅に上がることは間違いないが、整数演算のパフォーマンスはそれなりに落ちてしまう。
第2のポイントは、パイプライン段数をどこまで浅くするか。クラシカルな4~5ステージのパイプラインに戻せば消費電力はかなり抑えられる。ラッチ回路の削減分だけ電力消費は減り、CPU内のリソースも最小で済む。動作周波数が低くなる分だけ、キャッシュメモリの削減や、分岐予測機構の簡略化などの余地ができる。論理的には、インオーダ型の4~5ステージのCPUを作れば、最も効率がいいことになる。
●重視するアプリで変わるアーキテクチャ選択
しかし、そこまで軽量化すると、CPUコアのパフォーマンスは大きく削がれる。Intelが目標としている、Windowsがまともに使えるレベルのパフォーマンスを維持するには足りない可能性が高い。そのため、どの程度のパフォーマンスを目指すかによって、アーキテクチャのシンプル化の程度も変わってくる。
また、何のパフォーマンスを重視するかによっても変わってくる。メディアプロセッシング性能を重視するなら、CPUコアはシンプルでも、高クロック設計にすることが考えられる。例えば、最近のハイパフォーマンスCPUでも、ゲーム機向けのCPUは、Xbox 360とPLAYSTATION 3のどちらもアウトオブオーダを捨てている。CPUの制御系のトランジスタを大幅に削減して、CPUコアの小型化と効率化を図っている。その一方で、パイプラインは深くして、高クロック稼働を可能にし、メディアプロセッシングの性能を上げている。インオーダ実行なので、コンパイラによるスケジューリングによって性能を上げることになる。
もっとも、これはゲーム機という性格上、ソフト側が最適化してくれることを前提としている。レガシーソフトウェアを数多く持ち、また、プログラミングコミュニティが広いx86の世界では採用しにくいアプローチだ。
逆に整数演算の性能を重視するなら、パイプライン段数は抑え、その一方で、分岐予測を強化し、アウトオブオーダ型実行を採用した方がパフォーマンス/消費電力が上がる可能性がある。LPPが、Windowsをスモールデバイスで快適に使うことだけを考えるとすれば、その方がアプローチとしては適している可能性がある。
こうして見ると、目指す方向やアプローチによって、Intelが取ることができるアーキテクチャはかなり変わってくる。Intelがどのアーキテクチャを取るのかが、大きな境目となりそうだ。
□関連記事
【10月16日】【海外】大幅に強化されたAMDのクアッドコア「Barcelona」
http://pc.watch.impress.co.jp/docs/2006/1016/kaigai312.htm
(2006年10月23日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2006 Impress Watch Corporation, an Impress Group company. All rights reserved.