 |


■後藤弘茂のWeekly海外ニュース■機能拡張の割に小さいYonahのコア |
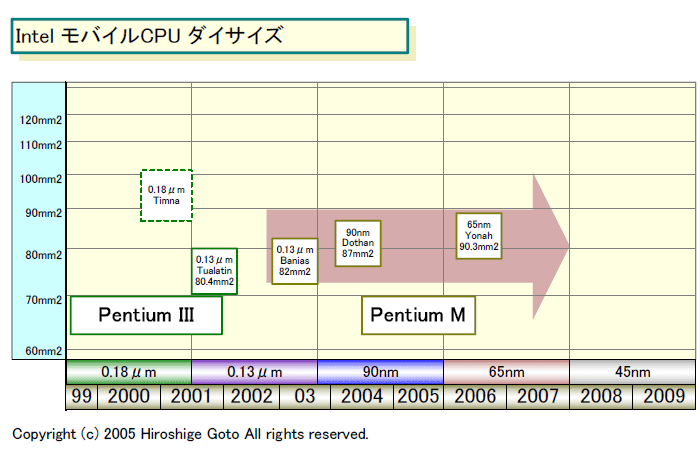
●ダイサイズを一定レベルに保つIntelのモバイルCPU戦略
Intelは、CPUのダイサイズ(半導体本体の面積)をほぼ一定に保とうとしている。IntelのモバイルCPUの系譜を見ると、前世代アーキテクチャの0.13μm版モバイルPentium III(Tualatin:テュアラティン)から、最新の次世代モバイルCPU「Yonah(ヨナ)」まで、ダイサイズは12%程度しか増えていない。
Yonah 90.3平方mm
Dothan 87平方mm
Banias 82.8平方mm
Tualatin 80.4平方mm
 |
| Intel Mobile CPU ダイサイズ移行図 PDF版はこちら |
4世代に渡って、ダイサイズは80~90平方mmのラインにピタリと並んでいる。IntelのデスクトップCPUのダイが200平方mm台から110平方mm程度の間で幅広く変動するのとは大きな違いだ。
ダイサイズを小さく保つ利点は、製造コストを下げるだけではない。モバイルCPUの場合は、ダイサイズ当たりの消費電力である電力密度を下げ、熱設計を容易にすることも重要なポイントだと推定される。また、CPU上のバンプの密度の問題からも、最低ラインのダイサイズは制約される。
ダイサイズをコンパクトにできる理由のひとつは、Banias/Yonah系を設計しているIntelイスラエルの開発チームが、小ダイサイズの設計に優れているためだと推測される。同チームが設計したPentium IIIベースのノースブリッジ&グラフィックス統合CPU「Timna(ティムナ)」は、0.18μmで100平方mm程度のダイサイズだった。
もうひとつの理由は、Banias/Yonah系のCPUコアは、もともとNetBurst系よりシンプルであることだ。
●トランジスタ数の増加が少ないYonah
 |
| Intel Mobile CPU トランジスタ数移行図 PDF版はこちら |
・Yonah 151.6M
・Dothan 140M
・Banias 77M
それに対して、IntelのMooly Eden氏(Vice President & General Manager, Mobile Platforms Group)は次のように説明する。
「トランジスタのほとんどはキャッシュで、CPUコアのトランジスタ数自体は比較的少ない。2MBのL2キャッシュが6トランジスタ(のSRAMセル)で構成されていて、さらに20%の(トランジスタ数の)オーバーヘッドがある。正確な数字は今わからないが、ラフに言うと約1億2千万(120M)くらいがL2キャッシュという計算になる」
この説明をベースにトランジスタ数を比較すると、右のような図になる。L2キャッシュSRAM部分は微細化である程度シュリンクしているが、ロジック部はトランジスタ数の割にダイエリアが大きくなる。そのため、ロジック部分の多いYonahでは、ダイサイズの割にトランジスタ数が少なくなる。
もっとも、この計算でもCPUコアが2個の割にはロジック部のトランジスタ数の増加が少ない。Eden氏によると、デュアルコアでは、両コアが共有する部分は2重に持たないためだという。CPUコアが2倍になっても、単純に2倍のトランジスタ数にはならないというわけだ。
もっとも、Banias/Yonah系のCPUコアが小さいのも確かだ。計算上、YonahではバスやL2キャッシュなどを除いた、純粋なCPUコアのトランジスタ数は1,100万ちょっととなる。だとすると、Pentium II/III世代のCPUコアとそれほど極端な差がなく、NetBurst系と比べるとはるかに少ないことになる。このことから、YonahもBanias系と同様に、トランジスタバジェットをできるだけ抑え、その中で性能向上を図ったマイクロアーキテクチャであることが推測できる。
●YonahのCPUコアの拡張
Yonahでは、デュアルコアによる性能向上だけでなく、CPUコアそれ自体の性能も、Dothanより向上されている。
□命令デコーダの改良
・uOPsフュージョンのSSE2命令への拡張
・128bit SSE2命令を3個のデコーダでデコード可能に
□SSE/SSE2命令最適化
・SSE2 ShuffleとUnpack命令を30%高速化
・整数除算(IDIV)の高速化
□SSE3命令サポート
・SSE3命令(10個)のサポート
□浮動小数点演算性能の向上
・FCW(FP precision/rounding control)レジスタのリネーミング
・データプリフェッチの拡張
・ライトアウトプットバッファの追加
 |
 |
| IDFにおけるYonah解説資料 |
全体で見ると、必要性の高そうな部分に的を絞った拡張のように見える。その中で面白いのは命令デコーダの部分の改良だ。
現在のIntel系CPUは、x86命令をデコーダで内部命令「マイクロオペレーション(uOPs)」に変換、実際の実行ユニットはuOPsを実行する。BaniasのベースとなったPentium IIIは3つのx86命令デコーダを持っていた。1個が複雑命令(Complex Instructions)をデコードできるコンプレックスデコーダ(Complex Decoder)、2つがシンプル命令(Simple instructions)をデコードできるシンプルデコーダ(Simple Decoder)だ。Banias/Yonah系も、この基本構造を継承している。
Banias/Dothan系アーキテクチャでは、128bit SSE命令はコンプレックスデコーダでしかデコードできなかった。だが、Yonahではこの制約は取り払われ、どのデコーダでもSSE命令をデコードできるようになったという。ちなみに、Yonahのシンプルデコーダは、SSE命令のサポート以外だけでなく、Pentium IIIのデコーダより進歩しているという。「シンプル以上の命令をデコードできる」とIntelのMooly Eden氏(Vice President & General Manager, Mobile Platforms Group)は語る。
Banias系アーキテクチャでは、uOPsフュージョンで、複数のuOPsを1個のuOPに融合させる。uOPsを融合させてuOPsの数を減らす利点は、スケジューラが管理するuOPsの数を減らすことで、命令スケジューリングの負担を軽くし効率化すること。Baniasマイクロアーキテクチャの発表時にIntelは「それぞれのuOPsがマシンリソースと電力を消費する。だからuOPsを減らすことで効率を上げ、電力消費を抑える」と説明していた。
しかし、Banias/Dothan系のuOPsフュージョには制限があり、SSE命令はuOPsフュージョンできなかった。Yonahではこの点も拡張され、SSEのLd-Op命令もuOPsフュージョンできるようになった。Yonahでは、DothanよりもさらにuOPsの数を減らすことで、効率化を図っていることになる。
 |
| IDFにおけるYonah解説資料 |
●SSE命令のuOPsフュージョン
下の図が、IDFで説明されたYonahのSSE命令のuOPsフュージョンの例だ。Dothanでは4個のuOPsに分解されていたSSE命令が、Yonahではたった1個のuOPに変換されている。面白いのは、このuOPsフュージョンの結果、SSE命令は1対1でuOPに変換されている点。つまり、x86命令は分解されていない。これだけを見ると、x86命令デコーダによって命令の名前が変えられただけのように見える。
 |
| IDFにおけるYonah解説資料 |
元々、x86命令のuOPへの変換の主目的は、複雑なx86命令を単純なRISCライクな内部命令に置き換えて、実行可能な命令から実行するアウトオブオーダ(out-of-order)型の命令スケジューリングを容易にすることだった。RISC風命令という意味は、一般的には、固定命令長で、固定フォーマット、ロードストア型の命令アーキテクチャを指す。
ロードストア型というのは、演算命令をレジスタ間演算だけに限定し、メモリアクセスは、ロードストア型のメモリ-レジスタ間命令だけに限定するアーキテクチャだ。x86命令にはメモリアクセスをともなう演算命令がある。例えば、加算命令で、オペランドの片方がメモリ、もう片方がレジスタである場合、CPUはメモリからデータをロードして、それをレジスタの値に加算する。しかし、この命令を演算命令とロード命令に分解すると、例えば、ロード命令を先に実行させて、データがレジスタにロードされる頃に、演算命令を実行するようにスケジュールすることができる。
ところが、YonahのuOPsフュージョンを見ると、メモリアクセスオペレーションと演算オペレーションは分離されず、1個の融合uOP(Fused uOP)に変換される。もちろん、1対1でも大きな違いはあり、Fused uOPになると、x86の複雑な命令フォーマット&命令長は解消され、後段でデコードしやすいフォーマットに変換されると見られる。変換後の命令はロードオペレーションを含む複合オペレーションになると説明されている。つまり、後でオペレーション単位に分解されることを前提にした命令フォーマットとなっているようだ。だから、uOPsフュージョンというわけだ。
●Yonahの実行パイプライン
uOPsでのオペレーションの複合化自体は珍しいアプローチではない。AMDもK7時代から、1個の内部命令「MacroOPs」に最大2個のオペレーションを複合させている。CPUが扱う内部命令の単位を大きくすること自体もここ数年のトレンドだ。例えば、PowerPC 970もインオーダ部では命令をパック化(4命令+1分岐命令)しておき、実行コアへの命令発行ステージで分解する。
もっとも、現在のCPUは、融合されたFused uOPsを実際に命令ユニットで実行する際には、演算OPとロードOPへと分解して、スケジューリングして実行する。ロードOPを演算OPよりも前に分離して実行しないと、演算ユニットは遊んでしまうことになる。そのため、Yonahのパイプラインでも、実際に命令ユニットにFused uOPsを発行する前に、Fused uOPsを分解、分解したuOPsを待機させるステージが必要になる。
ちなみに、YonahのuOPsフュージョンの例からは、DothanとYonahの実行パイプの相違も見えてくる。Dothanでは128bit SIMD(Single Instruction, Multiple Data)演算を、上位と下位の64bitずつの演算に分割している。Dothanでは、演算ユニットそのものが64bit SIMDになっていて、2パスで実行して128bit SIMD演算を行なっていると推定される。それに対してYonahは、128bitのSIMD演算器を持っているか、実行ユニットへの命令発行の前に4個の64bitオペレーションに分解するか、どちらかと思われる。後者の場合でも、Fused uOPsで融合できると推測される。
BaniasからYonahの、uOPsフュージョンとデコードの仕組みを考えると、YonahでのSSE命令のデコードとフュージョンの拡張も見えてくる。Dothanでは、おそらくSSEパイプラインに、Yonahのようなロード+演算命令の分解/スケジューリングの機構を持っていない。そのために、DothanではSSE命令はデコード段階で、実行ユニットがネイティブで対応できるロードストアアーキテクチャ型で、64bitのuOPsに分解しなければならない。おそらく、1対多のデコードに対応しているのはコンプレックスデコーダだけなので、SSE命令は1個のデコーダでしかデコードできなかったと推測される。
一方、Yonahでは、SSEパイプラインもフュージョンしたuOPsを分解するステージが設けられた。そのため、デコーダ側は1対1でuOPsに変換するだけで済む。そのため、シンプルデコーダでSSE命令もデコードができるようになったと考えると、納得がいく。
Yonahのデコード回りの改良が重要なのは、その先に控えるMeromもuOPsフュージョン型の内部命令アーキテクチャを取るからだ。「我々が電力効率を向上させるために、BaniasからMeromとそれ以降(のCPU)まで継続して行なっているのは、よりuOPsフュージョンを適用することだ」とIntelのJustin R. Rattner(ジャスティン・R・ラトナー)氏(Intel Senior Fellow, Director, Corporate Technology Group)と述べている。
□関連記事
【8月31日】【海外】Yonahの消費電力はなぜ少ないのか
http://pc.watch.impress.co.jp/docs/2005/0831/kaigai208.htm
(2005年9月6日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2005 Impress Corporation, an Impress Group company. All rights reserved.