 |
■大原雄介のEmbedded Processor Forum 2004レポート■Geode NXを投入したAMD |
例年のEPFでは、ARMとMIPSのせめぎ合いが見ものなのだが、今年はMIPSはConference初日のExpoのスポンサードをした以外にこれといって出番がなく、逆にCentaurに加えてAMDまでがx86系の講演をするという、EPFなんだかMPFなんだか判らないイベントになっていたのは不思議な事であった。
そこでレポート4本目は、AMDの発表に加えて、唯一のMIPS陣営として発表を行なったPMC-Sierraの新Interconnectの話をご紹介したい。
●AMD:肩すかしの基調講演
 |
| ARM社のCTOを勤めるMike Muller氏 |
しかし、“Embedded Technology Driving the Future of Consumer Technology”と題された同氏の講演は見事な肩すかし。同社は以前から、次世代のコンピューティングはCustomer Centric Computingであるという話をAMD64に絡めて主張しているわけだが、まさか今回Embedded絡みで同じ話を聞くことになるとは思わなかった。
ちなみに結論を急ぐと、x86コアがEmbeddedに最適という話で、「んじゃAlchemyはどうなるの?」とか思わず突っ込みを入れたくなるが、それはちょっと後にとっておくことにしよう。
 |
 |
 |
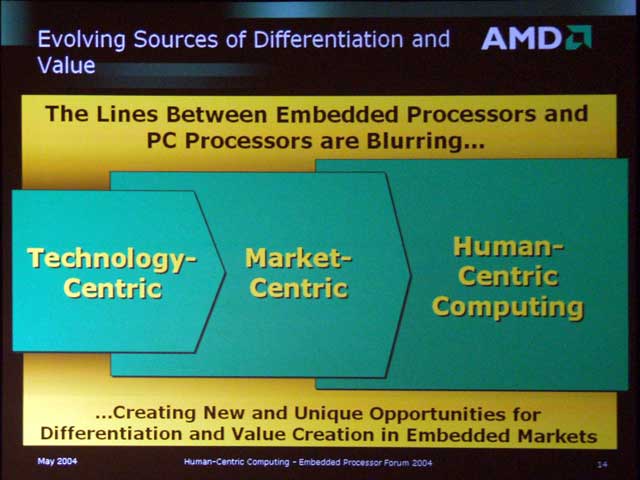
| 次世代のコンピューティングに求められる要素。これと似たものは、Athlon 64の発表で何度かお目にかかった | PC ProcessorもEmbedded Processorも、Human-Centric Computing(以前はCustomer-Centric Computingと言っていた気もするが、それだとClientのことなのか、End-Userの事なのかわかりにくいのでこう変えたのかもしれない。あるいは、いわゆるIA(Information Appliance)機器は(PCに比べ)よりユーザーに近いところに位置するから、あえてこう変えた可能性もある | AMD64とAMD Geodeで全ての機器を網羅する! という図。今から思えば、Geode NXの布石だったのかも |
●Geode GX2:省電力機構に関する詳細
ついで、Low Power Embedded Processorとして、AMD Geode GX2の詳細が発表された。同CPU、発表自体は昨年9月のCOMPUTEX/TAIPEI 2003だが、この際はあまり詳細な内容は明らかにされなかった。では今回は?というと、これまたC5J同様にほとんどどスルーされ、発表はもっぱら省電力機構に集中することになった。
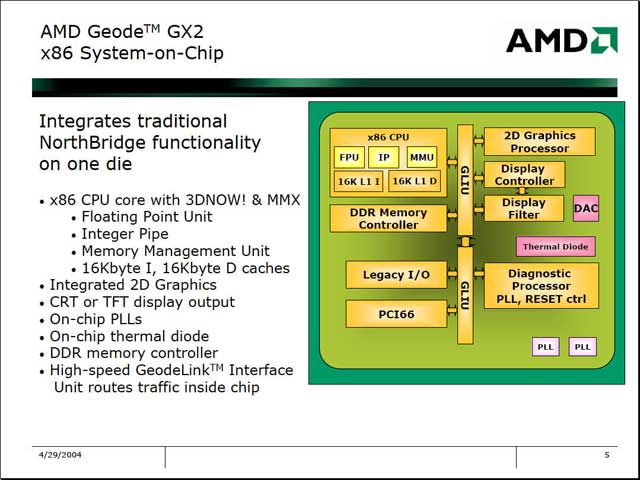
そもそもGeodeはGX1の時代から典型的なSoCと言えなくもないが、GX2ではコア内部にGeodeLinkと呼ばれるInterconnectを搭載したことで、よりSoCらしくなったと言える。ただ、SoCの割にコンパニオンチップとしてCS5535が必要というあたりがあまりSoCらしくないのだが、これはGX1世代との互換性を保つ事を念頭においたのだろう。
さすがにSATAどころかUltraATA/100にも未対応、USB 2.0にも未対応というのは組み込み用でもそろそろ苦しい気はするが、今のところこれをリプレースする予定は無いようだ。もっともこのあたりは、EPF 2004の翌週というタイミングで発表されたGeode NXで担うことになるから構わないのかもしれない(EPF 2004の最中は、そんな話はおくびにも出さなかった)。
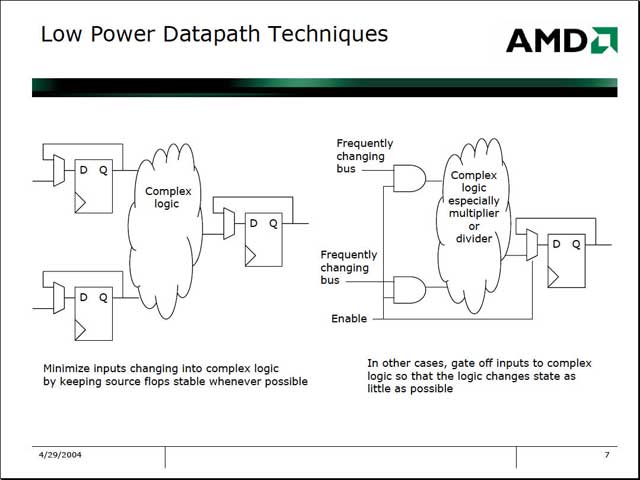
さて、肝心の発表であるが、物理的な構造に関しては、従来説明されていた以上のものはなかった。ではどんな話かというと、これがもうひたすら省電力絡みである。一般論として、データパスの消費電力を抑える方法として、ロジック回路の手前にDフリップフロップを突っ込み、データそのものではなくデータ変動を入力することで、回路動作を抑えるという方式や、これが難しい場合はClock Gatingにより不要時の消費電力を抑える方法が取られる。
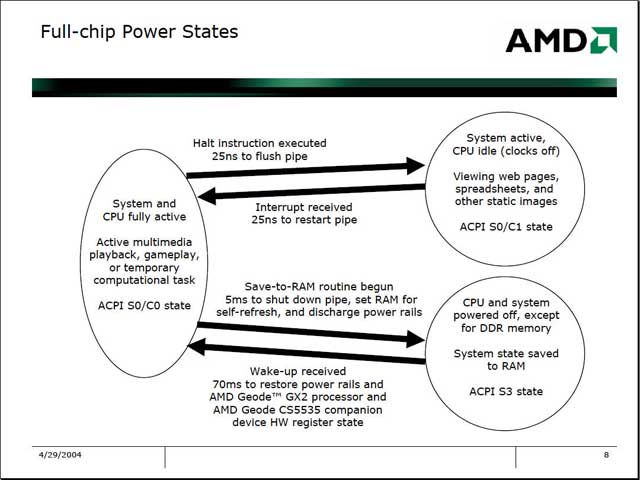
また、ACPIを積極的に使うことで消費電力を下げるのは当然だが、Embedded用途の場合レスポンス時間が問題になる場合がある。従って、各ステート間の遷移時間はなるべく短いほうが良い。このあたりについてもGX2は留意したそうで、結果として積極的にACPIを使える環境を構築したといえる。
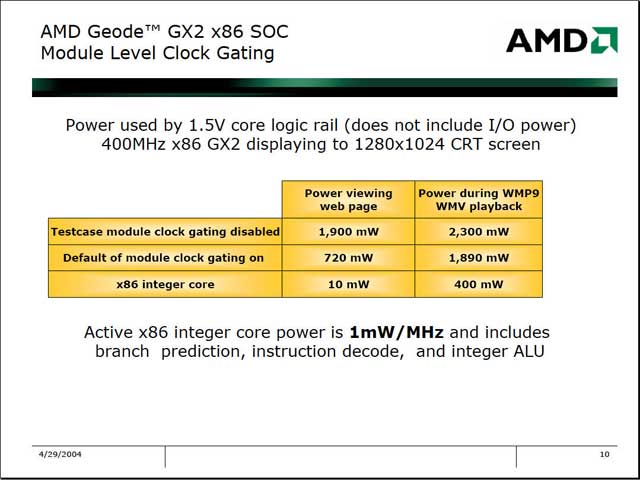
この結果として何が得られるかという話だが、Geode GX2ではWMVの再生時ですら1mW/MHz、Webブラウズでは0.025mW/MHzという驚異的な低消費電力を得られたことになる。この1mW/MHzというのは、同社のAlchemyシリーズとほぼ比肩しうる数字で、これまでAlchemyを当てていた低消費電力向けマーケットにx86を使える可能性が見えてきたことになる。
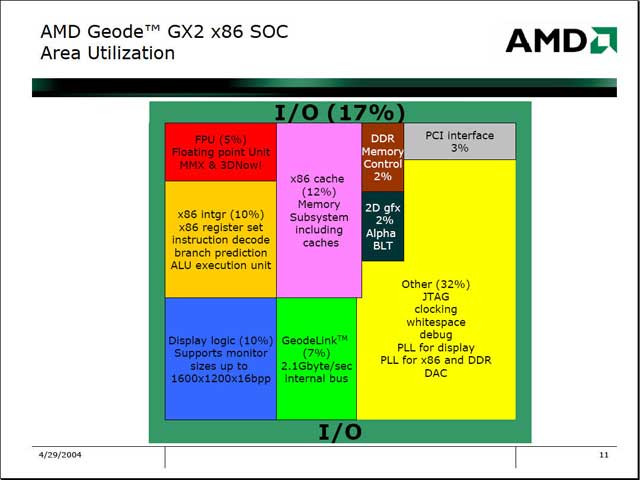
ちなみにコア内部の面積比も今回示されたが、CPU/FPUのコアは全体の15%程度、キャッシュを含めても30%未満であり、コアの大半は周辺機器で占められている事がわかる。確かにコアの消費電力よりも、その他の消費電力の方が多いのも理解ができるというものだ。その消費電力の割合をもうすこし詳しく示した図では、消費電力の大きな部分を占めているのは表示回路とI/O部であることが判る。
システムレベルでも、実はこれに似た傾向となる。VGAサイズの表示画面を使った場合のシステムレベルの消費電力の内訳も示されたが、C0ステートでは7W近い消費電力となるものの、このうちGeode GX2は実質2W少々で、むしろTFTパネルとバックライトの方が消費電力が大きくなる。このTFTの部分はS3(サスペンド)にならない限り減らないわけで、結果としてIdleステートなどでは、大半がTFTパネルという事になる。
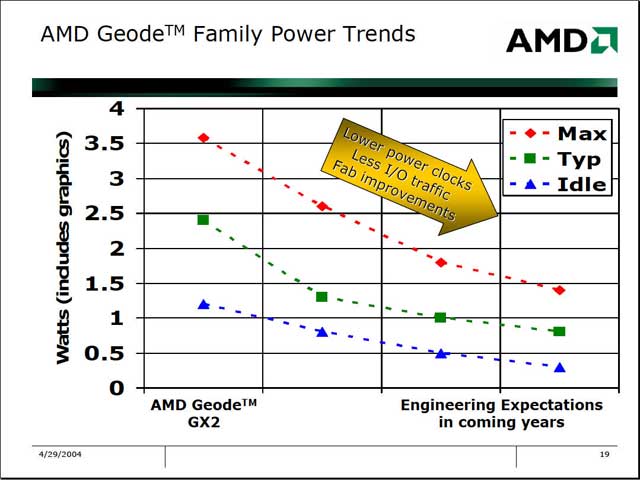
今度は角度を変えて消費電力の変化を見てみると、例えばRISCコアの400MHzCPUとGX2/400MHzで同じ処理(iBenchのHTMLダウンロード)を行なった場合、GX2はピーク時の消費電力こそ大きいものの、数秒で0に近くなるが、RISCコアでは長時間稼動するため、トータルの消費電力ではGX2が有利である、としている。これを更に拡張して、「単位処理を行なうのに必要な消費電力」なるものを比較すると、Geode GX2-400が圧倒的に有利、という結果まで今回は示された。最後に簡単なロードマップとして、今後更に消費電力を下げた製品を投入することが語られた。
●イベント終了後にGeode NXを発表
 |
| Senior Manager, Design EngineerのSteve Kommrusch氏。前日たまたま隣で昼飯を食べていたので聞いたところ、やはりNSから来た方だそうだ |
このマーケットはVIAがEdenプラットフォームという形で既に大きなシェアを奪っており、ここがまさしく抜けていたわけだ。この話は以前からもあったことで、これを同社のPCS(Personal Connectivity Solutions)グループの人に聞くと、「いやK6-2-EやK6-III-E、Athlon XPなどがあるよ」という返事は返ってくるものの、力の入れ方が明らかに違っており、現実問題として大穴があいていたわけだ。
これに関する質問の答えはEPF2004では得られなかったが、イベントの明けた24日(米国時間)、AMD Geode NXの発表という形で回答が出された。このGeode NX、アーキテクチャはAthlon XPそのままである。L1が64KB 命令/データ、L2がUnified 256KBで、パッケージはOBGAの462ピンと、そのまんまの構造になっている。FSBは266MHzで、動作クロックは1GHz(Geode NX 1500)/1.4GHz(Geode NX 1750)だが、注目すべきはその消費電力である。Geode NX 1500は、Vcc 1VでTDPがTypical 6W/MAX 9W、NX 1750はVcc 1.25VでTDPがTypical 14W/MAX 25Wとなっている。特にこのNX 1500、Edenプラットフォームの7Wという数字を意識しているのは明白である。
さらに露骨なのはベンチマーク結果で、Nehamiah 1GHzとNX 1500のベンチマークという形でその優位性をアピールしている。Edenプラットフォームが握っているマーケットの重要性を、AMDは良く理解しているようだ。
こうなると、初めてGeode GXの意味が出てくるというものである。勿論、まだAMDには課題は多い。特にプラットフォームを作る上で必須のチップセットを自社供給していないのは、いろいろと問題は多い。開発用ボードがVIAのKM400Aを搭載したMini-ITXというあたり、今後に向けた課題の大きさが偲ばれるというものだが、そうであっても明確に意思表示をしたことは大きい。これで初めてAMD64とGeodeの世界が、性能・消費電力的にうまく連続したからだ。こうなると、GX2は無理に性能を上げる方向に振る必要はなく、むしろ低消費電力に振るのは極めて筋が通った方法論であることは間違いない。
とはいえ、これが成功するためには、やはりGeode NXがそれなりのシェアを確保することが重要である。現在のVIAのEdenと同程度の支持をカスタマーから得られるのだろうか、むしろ焦点はそちらに移ることになりそうだ。
 |
 |
 |
| GX2の内部構造。パイプラインの詳細とかは一切不明のまま。この他の公開情報といえば、GeodeLink(内部のGLIUとかかれている部分)が2GB/secの転送速度を持つことぐらいのようだ | 左は要するにDフリップフロップを経由することで、信号自体を入力するのではなく、信号の変位を入力する。これにより、データ変動が減るため消費電力が節約できる。一方右は典型的なClock Gatingで、“Enable”の信号線のコントロールで、回路への信号入力を止められるため、それで更に消費電力を下げられる。これを徹底すると、Complex Logicへの電源供給も止めたりする形になるが、これは回路が複雑になるため、ダイコストの増加との睨めっこになる | コア自体はSingle Issueのパイプラインで動作速度も400MHzだから、性能的にはVIA C3/533MHzを更に下回るのは確実で、その割にというと失礼だが、案外にC0とC1ステート間の遷移は早い。S3→S0のWakeup Eventの伝達が70msというのも、この手のプロセッサとしては高速な部類に入ると思う |
 |
 |
 |
| もはや消費電力は、CPUコアよりもそれ以外の方が桁違いに多くなっている事がわかる。ついでに言うと、Clock Gatingの威力もここで確認できる。念のために言っておけば、Alchemyの場合は周辺回路を含めて1mW/MHz以下に抑えているので、今すぐ置き換え可能というレベルにはまだ達していない | とにかく最初の4年で約1億ドルという投資が必要なわけで、もう小さなベンダーでは開発すらままならない感じだ | Chip I/OはおそらくGeodeLinkに掛かる部分であろう。これはまぁどうしようもないとして、Displayに関しては表示性能を求める限りいかんもしがたいというのが実情だろう。これが例えばQVGAサイズでOKとかいう話であれば、また比率は変わってくると思われる |
 |
 |
| S3ステートでは、DDR SDRAMの内容を保持するために多少電力が必要ではあるが、それ以外は全部0というわけだ。ちなみに一番右端の“10% on, 90% Idle”というのが一般的な使われ方のパターンだとしている | このRISC 400/100が何かというのが明確にされていないのでこれだけではなんともいえないのだが、おそらくはAlchemy Au1000あたりを使ったWindows CEのClientではないかと思われる |
 |
 |
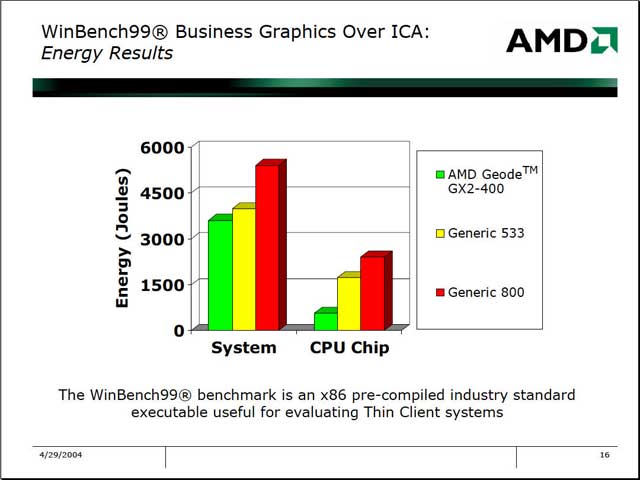
| 縦軸の単位はエネルギー(J)で、1W=1J/secである。つまり、クライアント上でWinBench99を動かす場合の消費電力の累計ということだ。ちなみにICAはIndependent Computing Architectureの略で、Thin Clientを任意の通信プロトコル(TCP/IP、IPX、SPX等)経由で動かす技術。察するにGeneric 533/800は、VIAのEdenではないかと思う | 現状はTSMCの0.15μmプロセスを使っているから、これを0.13μm→0.11μm→90nmと縮小してゆくという話ではないか |
【お詫びと訂正】初出時にキャプションの一部が誤っておりました。お詫びして訂正させていただきます。
●PMC-Sierra:SoC製品の投入
MIPS勢が鳴りを潜めた今回、唯一発表を行なったのがPMC-Sierraである。ただRM9150というこの新製品、CPUコアは既存のRM9000シリーズと同じもので、SoCを使って周辺回路を統合したのが唯一の違いである。ただ、その方法論が注目に値するので、ちょっとご紹介したい。
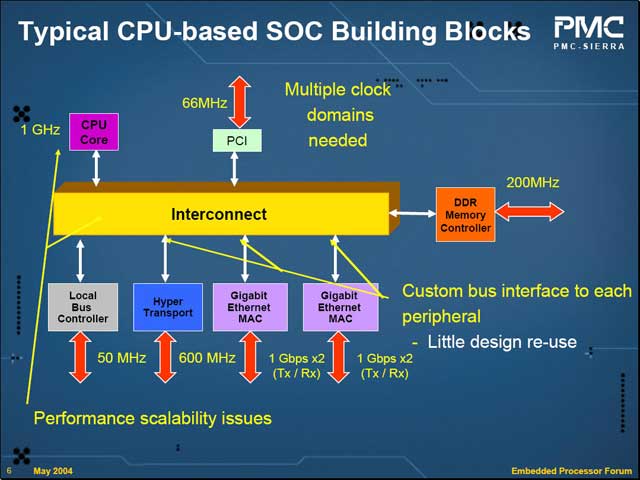
一般にSoC製品は、要するにCPU Coreやメモリコントローラ、各種周辺回路をInterconnectで結んだ構造になる。このInterconnectを複数搭載する(例えばARMのAMBAは高速なAHBと低速なAPBがあり、CPUやメモリコントローラ、高速なI/OはAHBで接続、低速なI/OはAPBで結び、AHBとAPBをブリッジで接続する)場合もあるが、基本形は下図のような構造となる。ここで複数のデバイスが動作する場合、基本的には各デバイスはメモリとアクセスを行なうことになる。ここで必要とされるのは、次のファクターだ。
・各デバイスとの接続のスループットが高い事
・同時に多数の転送を取り扱えるパラレル性
・メモリアクセスのレイテンシが低い事
 |
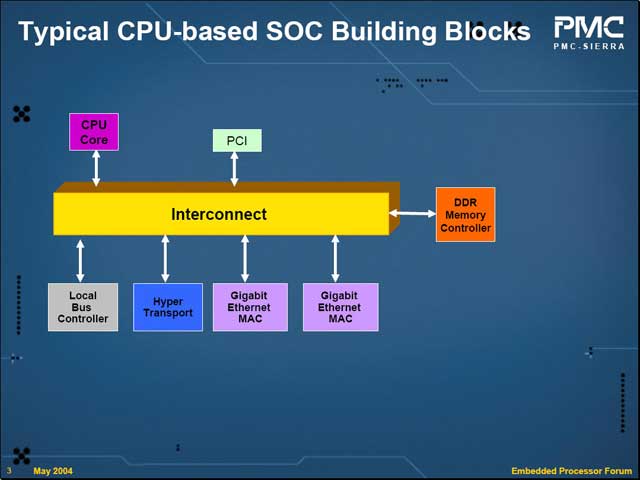 |
| Principal EngineerのJohn Kinsel氏 | この発表のテーマはInterconnectなので、異様にInterconnectが強調された図になっている |
勿論この目的のために、例えばAMBA 3.0とかOCPといったInterconnect専用インターフェイスがあるわけだが、コストが余分に掛かることは事実だし、必ずしも満足ゆく結果が得られるとは限らない。これは帯域に関してもいえる。
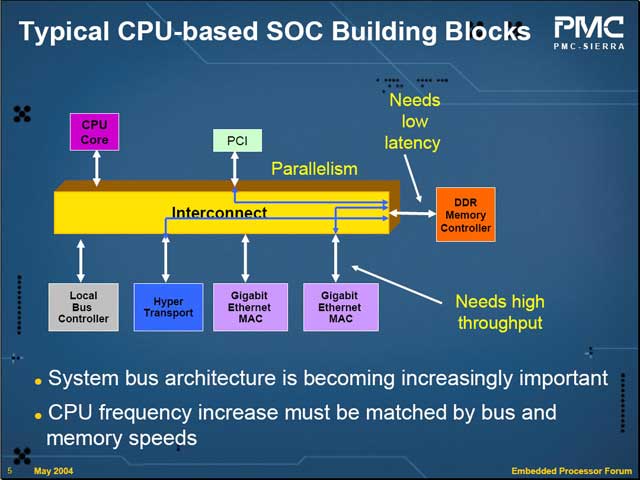
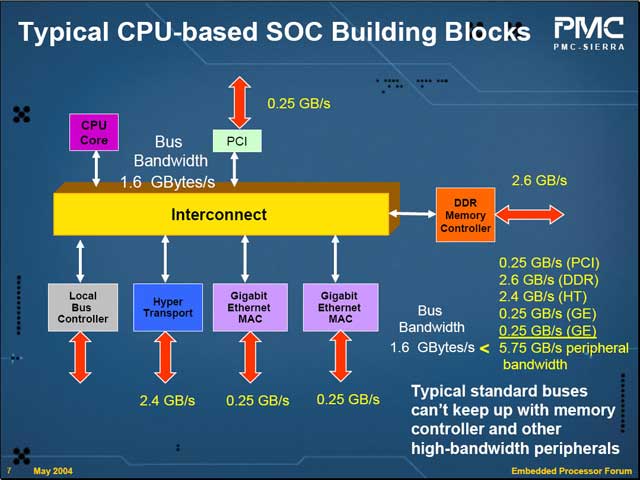
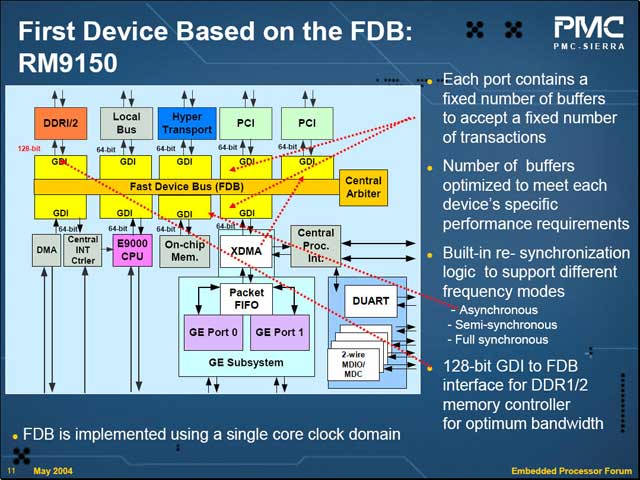
例えばRM9150は、NASやルーター向けの製品を目指しているわけだが、このために高速なインターフェイスをいくつか内蔵している。これらがフルに動作するために必要なバス帯域を積み上げてゆくと、5.7GB/secにも達してしまい、通常のInterconnectでは全然間に合わないという計算になってしまう。
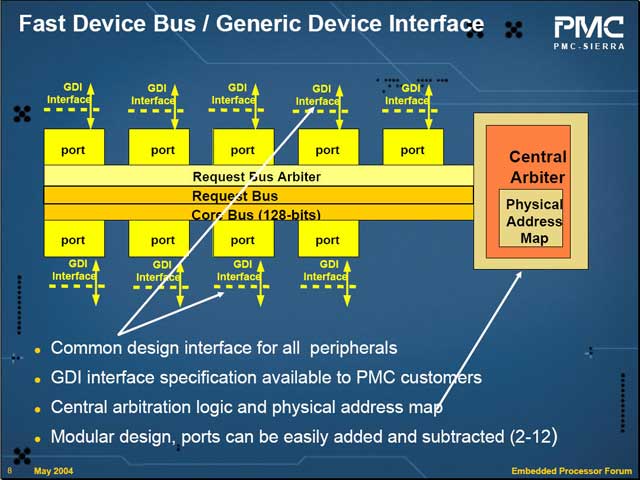
そこで今回PMC-Sierraが投入するのが、Fast Device Bus(FDB)と呼ばれるInterconnectである。このバス、RequestラインやBus Arbiterをデータバス(Core Bus)に分離し、データ幅を128bitとしてかなりのスループットを確保することに成功している。
もうひとつ面白いのは、GDI(Generic Device Interface)と呼ばれる汎用のインターフェイスをバス側に持たせたことだ。まずFDB自身は、複数のマスターデバイスを許すシェアードバス方式を取るが、リクエストバス/アービタを分離したため、同時に複数のリクエストを処理することで転送効率を上げることが可能になっている。またGDIは任意のデータ幅に変更が出来、同期/非同期/半同期のいずれもカバーする。
このFDBとGDIの組み合わせにより何が得られるかというと、インプリメントと検証の時間短縮である。SoCの場合、一般には周辺回路をIPとして購入してきて、それをInterconnectに接続するわけだが、その際にはInterconnectに合わせて周辺回路側のIPに手を入れる必要があるのが原則だった。従ってIPの検証に余分な時間が掛かっていたわけだ。ところがFBDの場合、GDI側をIPに合わせて変更すればそのまま接続できるため、IPへのインプリメントや、IP自体の検証の時間を短縮できることになるというのが最大の特徴である。今回のRM9150は、こうしたことの確認の意味をも持った製品というわけだ。
さて問題はこのFDBの目的である。セッションの後で、同社のAnna Chiang氏(Sr. Strategic Marketing Manager, Microprocessor Product Division)に話を伺ったのだが、別にPMC-SierraはこのFDBをIPコアとして他社にライセンスするとか言った計画はなく、あくまで自社で使うのが前提であるという。大体同社はFabを自社で持っているわけではない。ファウンダリ(主にTSMC)を使って生産しているわけで、ここでSoCのIP用Interconnectを作ったからといって、これでビジネスを行なうのは非常に難しい。しかも確かにFDBは高速かもしれないが、時代はスイッチに向かっている。OCPにせよAMBA 3.0のAXIにせよ、スイッチを前提とした方向性に向かっているのが現状で、敢えてここでシェアードバスを投入するのはちょっと時代に逆行している感じすら受ける。
これについて、Chiang氏の答えはなかなか興味深かった。そもそもPMC-Sierraは、MIPSからISAライセンス(アーキテクチャライセンス)を受け、独自の64bitプロセッサを製造している。ハイエンドのE9000は最大1GHzの動作速度を持ち、Embedded Marketでは最速プロセッサの1つである。
このE9000をトップに、E5000/E7000といったシリーズの製品を市場に投入し、複写機/プリンタやルーター/NASといったマーケットに大きなシェアを持っているわけだが、あくまで同社はCPUを提供する形を取っており、最近のSoCチップと比較すると単機能製品がほとんどだ。RM9150はこれに対する回答の最初のもので、今後は多くのSoC製品を投入する形で市場の要求にこたえてゆく計画なのだ。
ここで問題なのはTAT(Turn Around Time)である。PMC-Sierraで全ての周辺回路を作っていては時間とコストが掛かりすぎるから、適切なIPコアを入手してSoCチップを作り上げるのは、TATを短縮する上で重要な事だが、ところが上述のようにIPを買ってきてもそのまま使えるとは限らない。特に最近Interconnect性能の重要性が認識されているから、AHB/APBで良しとはできないし、だからといって高速なバスを入れると今度はIPの手直しが必要になる。つまり、多様なSoC製品をIPの手直し無しで投入するための方法が、FDBとGDIというわけである。
勿論FBDのシェアードバスの性能の限界は同社もよく理解しており、ハイエンドのRM9200はInter connectにクロスバースイッチを使っている。FDBはむしろミッドレンジからローエンドに掛けての製品展開を容易にする目的で導入するもので、ミッドレンジは引き続きFDBを、ローエンドにはFDBのLite版をそれぞれ使ってゆくことで、迅速に製品展開を増やす事を可能にしようという意図である。もっと将来の計画としては、「顧客の持つIPコアを統合する事も、GDIによって可能になる」(Chiang氏)といった話もある。もちろんPMC-Sierraが完全なワンストップサービスを提供するという意味ではないが(そういうオプションも考えられる、という程度)、そうした含みを持たせた事業展開がFDBによって可能になりえるわけだ。
従来のSoCの考え方からすれば、PMC-SierraはE9000をIPコアとして提供するか、もしくはPMC-SierraがInterconnectや周辺回路をIPコアとして購入し、RM9150を作るといった方法が典型的なわけだが、そこから一歩踏み込んだ形のアプローチを今回見せてもらったわけで、今後はこうしたパターンが他のメーカーからも見られるかもしれない。
 |
 |
| 別にSoCに限らず、システムバスに求められる要件としては一般的なものではあるが、SoCの場合一度作ってしまうと後から「やっぱりもうちょっと性能を上げたほうがいい」とか言って調整するわけには行かないので、設計段階でこれらを十分確保する事が求められる | 速度やバス幅は回路によってまったく違うので、これらに対応するのは大変である。AHBなりAPBといったインターフェイスは、これのインプリメントを容易にする一つの解ではある。PCIインターフェイスに比べると遥かに簡単な回路で済む(=ダイサイズの肥大化を最小限に抑えられる)が、性能面での弱みはいかんともしがたく、それがAMBA 3.0のAXIインターフェイスの登場を促したわけでもある |
 |
 |
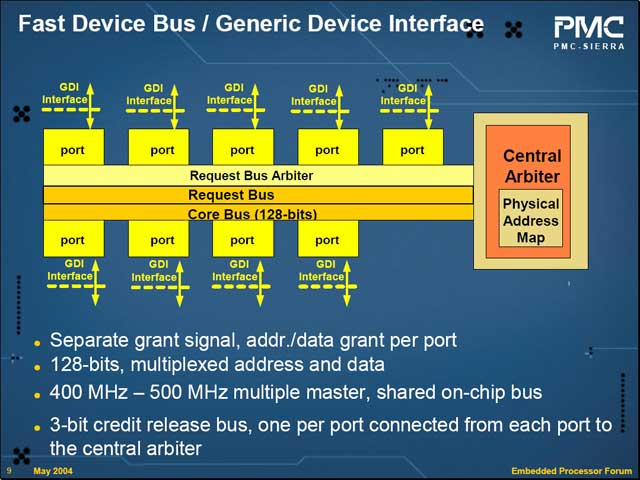 |
| 実はこのInterconenctが重要、というのは割と多い話である。例えばブロードバンドルーターのスループットを見る場合、単にCPUコアの性能だけを見てもルーティング性能が一致しない場合は多い。Interconnectが高速なチップだとそれほどCPUコアが高速でなくてもスループットが高く、逆にInterconnectが低速だとCPUコアが高速でもそれほどスループットが出なかったりする | FDBの模式図:最大12デバイスまで接続可能になっている | アービタの管理は右側のCentral Arbiterが行なうが、ここで同時に3つのデバイスが接続可能(アービタが3bitで管理されている)となっている |
 |
 |
| RM9150の内部構造。今回は全てのデバイスが64bit(メモリコントローラのみ128bit)で接続されているが、必要なら32bitとか16bitも可能である。一方転送速度の方はデバイスによってまちまちで、これらの差は全てGDIが吸収する | 将来の計画:Lite FDBは、接続できるデバイスの数やバスのスピードなどを多少抑え、コストを下げたものになるらしい |
□Embedded Processor Forum 2004のホームページ(英文)
http://www.mdronline.com/epf04/index.html
□AMDのホームページ(英文)
http://www.amd.com/
□Geode NXベンチマーク結果(英文)
http://www.amd.com/us-en/ConnectivitySolutions/ProductInformation/0,,50_2330_9863_10837^10861,00.html
□PMC-Sierraのホームページ(英文)
http://www.pmc-sierra.com/
□関連記事
【5月24日】AMD、組み込み向けx86プロセッサ「Geode NX」
http://pc.watch.impress.co.jp/docs/2004/0524/amd.htm
(2004年5月26日)
[Reported by 大原雄介]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp 個別にご回答することはいたしかねます。
Copyright (c) 2004 Impress Corporation All rights reserved.